![[AWS Workshop] これから学ぶS3基礎](https://devio2023-media.developers.io/wp-content/uploads/2019/05/amazon-s3.png)
[AWS Workshop] これから学ぶS3基礎
この記事は公開されてから1年以上経過しています。情報が古い可能性がありますので、ご注意ください。
こんにちは。
ご機嫌いかがでしょうか。
"No human labor is no human error" が大好きな吉井 亮です。
クラスメソッドは2020年4月にマイグレーションサービスを刷新し企業のクラウド移行をさらに支援していきます。
クラウド移行を成功させるための一つの要因として CCoE (Cloud Center of Excellence)組織を自社内に構築することが重要だと考えています。
この支援をサービスに盛り込んでおります。
CCoE 支援のなかで、顧客要員の AWS スキルのキャッチアップをお手伝いしたいと考えています。
その教材として「S3 基礎」を用意しようと思っています。資料を公開します。
S3基礎
S3 (Simple Storage Service) はオブジェクトストレージサービスです。
オブジェクトストレージは、データをファイル / ディレクトリ / ブロックではなくオブジェクトとして扱います。
従来のファイルストレージのような階層構造ではなく、データとメタデータによって管理を行います。
S3の概念
S3 を理解するために必要な概念は以下の通りです。
- バケット
- オブジェクト
- キー
- リージョン
- Amazon S3 のデータ整合性モデル
バケット
バケットはオブジェクトを格納する”容器”だと考えてください。
S3 の全てのオブジェクトはバケットに格納 (保管) されます。
バケットを作成する際には以下の規則があります。
- バケット名は全世界で一意にする必要があります
- バケット名は、DNS 命名規則に沿って命名する必要があります。
- バケット名は、3~63 文字以内にする必要があります。
- 大文字またはアンダースコアをバケット名に含めることはできません。
- バケット名の先頭は小文字の英数字にする必要があります。
- バケット名は、1 つのラベルまたは一連の複数のラベルとして指定します。隣り合うラベルは単一のピリオドで区切ります。
- バケット名には、小文字の英文字、数字、およびハイフン (-) を含めることができます。
- 各ラベルの先頭および末尾は、小文字の英文字または数字にする必要があります。
- バケット名は IP アドレスの形式 (192.168.5.4 など) にはできません。
- 仮想ホスティング形式のバケットを Secure Sockets Layer (SSL) で使用する場合、SSL ワイルドカード証明書はピリオドを含まないバケットにのみ一致します。この問題を回避するには、HTTP を使用するか、または独自の証明書検証ロジックを記述します。
- 仮想ホスティング形式のバケットを使用するときは、バケット名にピリオド (「.」) を使用しないことをお勧めします。
バケットへのアクセス
バケットへのアクセス方法は複数存在します。
マネジメントコンソール
AWS マネジメントコンソールからバケットへアクセスします。
ほぼ全ての操作を実行可能です。
仮想ホスティング形式
プログラミングアクセスはこの形式になります。
仮想ホスティング形式の URL。
https://{バケット名}.s3.{リージョン}.amazonaws.com/{キー名}
例)
https://my-bucket.s3.ap-northeast-1.amazonaws.com/example.jpg
パス形式
パス形式も利用可能ですが、2020年9月30日以降に作成されたバケットは仮想ホスティング形式のリクエストのみサポートになります。
ですので、基本的には仮想ホスティングを利用します。
パス形式の URLは以下です。
https://s3.{リージョン}.amazonaws.com/{バケット名}/{キー名}
例)
https://s3.ap-northeast-1.amazonaws.com/my-bucket/example.jpg
S3 アクセスポイント
仮想ホスティング形式では、バケットに1つの URL が作成されます。
バケットのアクセス制限を設定する場合、バケットポリシーを記述していきます。(後述)
プログラムとバケットが1対1であれば、そこまで難しくはありません。これが N 対1になっていくとポリシー記述の難易度が高くなっていきます。
これを解決するために、アクセスポイントを使用します。
アクセスポイントを用いると接続に対して1つのポリシーで制御が可能になります。
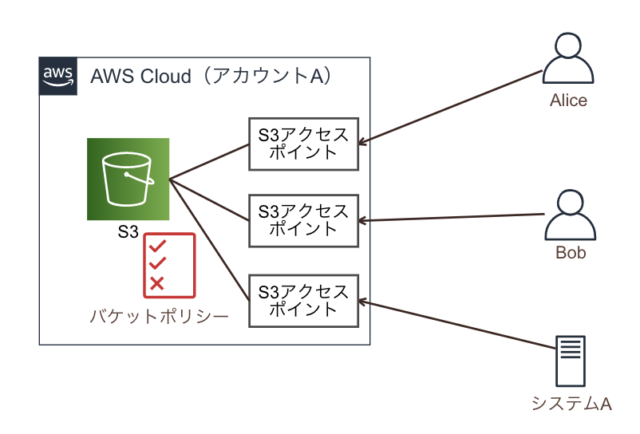
https://dev.classmethod.jp/articles/explain-the-good-point-of-s3-access-points/ より引用
アクセスポイントの URL は以下です。
https://{アクセスポイント名}-{AWSアカウントID}.s3-accesspoint.{リージョン}.amazonaws.com.
S3:// を使用したバケットへのアクセス
一部のサービスでは S3:// という形式でバケットへアクセスします。
S3://{バケット名}/{キー名}
オブジェクト
データとメタデータで構成されるエンティティです。
ファイルストレージで考えるところの ファイル だと思ってもらうと理解しやすいと思います。
メタデータはオブジェクトの属性情報です。
最終更新日、サイズ(バイト)、Content-Type などの他にユーザー定義のメタデータを持たせることが可能です。
キー
バケット内のオブジェクトの固有の識別子です。
ファイルストレージで考えるところの ファイルパス です。
たとえば、https://doc.s3.amazonaws.com/2006-03-01/AmazonS3.wsdl という URL では、「doc」がバケットの名前で、「2006-03-01/AmazonS3.wsdl」がキーです。
キー名にマルチバイトを含めることは可能ですが、コード処理の手間を考慮して、プログラミングアクセス時には以下の文字のみを使用することをおすすめします。
- 数字
- 英字(大小)
- ! - _ . * ' ( )
リージョン
バケットはリージョンを指定して作成します。
レイテンシーとコストを最小限の抑えるため、S3 アクセス元クライアントと同じリージョンにバケットを作成します。
Amazon S3 のデータ整合性モデル
S3 のデータ整合性モデルは 結果整合性 です。
S3 は複数の物理機器でデータを複製して高可用性を実現しています。
あるオブジェクトを更新すると、その更新は複数の物理機器でレプリケーションされます。レプリケーションされている期間に GET リクエストがあった場合、更新前にオブジェクトが返される可能性があります。
S3 を使用する際には以下のケースが発生する可能性があることを理解します。
- 新しいオブジェクトを PUT した直後は、一覧に表示されない
- 既存のオブジェクトを上書きした直後は、古いデータが返される
- 既存のオブジェクトを削除した直後は、削除したはずのデータが返される
- 既存のオブジェクトを削除した直後は、削除したはずのデータが一覧に表示される
読み込みは上記の通りです。書き込みはどうでしょうか。
S3 には書き込み排他やロック機能はありません。
同じキーに対して複数の PUT があった場合はタイムスタンプが新しいリクエストが優先されます。
複数キーにまたがるアトミックな更新、つまりトランザクションを実現する方法もありません。
これらを実現したい場合はアプリケーションで実装するか、RDS (RDBMS) を選択することになります。
S3機能
S3 の特徴的な機能を紹介します。
ストレージクラス
S3 では保存するオブジェクト用の幅広いストレージクラスが提供されています。
ユースケースや要件に合わせて最適なクラスを選択することが可能です。
| ストレージクラス | 説明 | 設計上の耐久性 | 設計上の可用性 | ユースケース |
|---|---|---|---|---|
| S3 スタンダード | デフォルトの S3 | 99.999999999% | 99.99% | アクセス頻度が高い、高パフォーマンス |
| 低冗長化 | スタンダートより冗長性を落としている。現在は使用しない。 | 99.99% | 99.99% | 現在は使用しない |
| S3 Intelligent-Tiering | 30日間アクセスのないオブジェクトが自動的に料金の安いエリアへ移動する | 99.999999999% | 99.9% | アクセスパターンが予測不能で長期保存が必要なケースに最適 |
| S3 スタンダード-IA | スタンダートより保存料金が安いが、操作料金が高い | 99.999999999% | 99.9% | プライマリまたは再作成できないデータのコピーで使用 |
| S3 One Zone-IA | スタンダード-IAの可用性を下げたクラス | 99.999999999% | 99.5% | アベイラビリティーゾーンでの障害発生時にデータを再作成できる場合や、S3 クロスリージョンレプリケーション設定時のオブジェクトレプリカに使用 |
| S3 Glacier | 保存料金が安く長期保管に向いている。取り出しには数分~数時間を要する。 | 99.999999999% | - | 複数年保管のバックアップ |
| S3 Glacier Deep Archive | 最も低コストで保管できるクラス | 99.999999999% | - | 7年~10年のデータコンプライアンスを満たす保管 |
ストレージクラスの選択
基本的には「S3 スタンダード」で使用を開始します。
オブジェクトサイズ、オブジェクト数、リクエスト数を実測し、データコンプライアンスとコストに最も合致するクラスへ変更していきます。
例えば、Glacier は保存データあたりの料金はスタンダートに比べて安価ですが、リクエスト料金は高くなります。
ライフサイクル設定によって◯◯日後に Glacier へ移行を考えている場合は、Glacier リクエスト料金を払って移行したほうが、スタンダードを使い続けるより安くなることを計算することが大切です。
バージョニング
バージョニングを使用すると、1 つのバケットで複数バージョンのオブジェクトを維持できます。
バージョニングを使用することで、意図しない上書きや削除からデータを保護します。
バージョンニングはデフォルト無効です。必要な場合は明示的に有効にします。
バージョニング有効
以下はバージョニングの概念を示しています。
photo.gif にはバージョン ID = 111111 が付与されています。
このオブジェクトを上書き PUT した場合、バージョン ID = 121212 が付与された photo.gif が作成されます。
バージョン ID = 111111 は削除されません。
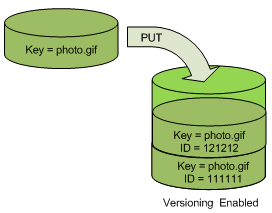
https://docs.aws.amazon.com/ja_jp/AmazonS3/latest/dev/ObjectVersioning.html より引用
オブジェクト削除
バージョニングを有効にした状態でオブジェクトを削除すると最新のバージョンが削除されます。
以前のバージョンは残っているので、操作により復元することが可能です。
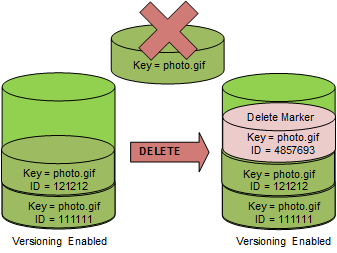
https://docs.aws.amazon.com/ja_jp/AmazonS3/latest/dev/ObjectVersioning.html より引用
この場合 GET リクエストは最新バージョンを取得しようとするので HTTTP 404 が返ります。

https://docs.aws.amazon.com/ja_jp/AmazonS3/latest/dev/ObjectVersioning.html より引用
オブジェクトを完全に削除したい場合は全てのバージョンを削除するようにします。
ライフサイクル
バケットに保存されているオブジェクトのコスト効率を向上させるためにライフサイクル管理を行います。
以下の2つのアクションを活用してライフサイクルを適切に設定します。
- 移行
- 有効期限
移行
別のストレージクラスへ移行します。
例えば、オブジェクト作成後1年が経過し、さらに6年の保管が必要、かつ、アクセスはほぼ無いものは Glacier へ移行するなどです。
保存料金の安いクラスへ移行することがほとんどです。クラス移行にはリクエスト料金が発生します。リクエスト料金が保存料金を超えないように予め計算しておきます。
有効期限
オブジェクト更新日をベースに、指定した日数を経過したオブジェクトとバージョンを自動的に削除します。
有効期限が過ぎたオブジェクトは UTC 00:00 に削除キューに入り非同期で削除されます。
S3 Intelligent-Tiering、S3 スタンダード-IA、または S3 One Zone-IA ストレージにあった期間が 30 日未満のオブジェクトを失効させる S3 ライフサイクル 失効ルールを作成すると、30 日分の料金が発生します。
S3 Glacier ストレージにあった期間が 90 日未満のオブジェクトを失効させるライフサイクル失効ルールを作成すると、90 日分の料金が発生します。
S3 Glacier Deep Archive ストレージにあった期間が 180 日未満のオブジェクトを失効させるライフサイクル失効ルールを作成すると、180 日分の料金が発生します。
レプリケーション
異なるバケット間で非同期にオブジェクトをコピーすることが可能です。
バケットは同じリージョンでも異なるリージョンでもレプリケーション可能です。
新規オブジェクトの99.99%が15分以内にレプリケートされるよう設計されています。
レプリケーションを使用するケース例は以下です。
- データ保管要件を満たす
- 物理的に離れたリージョンにデータをレプリケートします
- レイテンシーの低減
- S3 をデータソースとするアプリケーションをワールドワイドで展開している場合、バケットをレプリケートするとレイテンシーが低減できる可能性があります
- データ集約
- データやログを複数バケットに出力している場合、レプリケーションを使用すると最終的に1つのバケットに集約することが可能です
- 環境間のデータ複製
- 本番データを使用して検証を実施したい場面で有効です
バッチオペレーション
複数のオブジェクトに対してバッチオペレーションを実行することが可能です。
バッチオペレーションでは以下の5つのオペレーションをサポートしています。
| オペレーション | 説明 |
|---|---|
| PUT オブジェクトコピー | 指定したオブジェクトを他のバケットへコピー |
| オブジェクトの復元を開始する | S3 Glacier または S3 Glacier Deep Archive にアーカイブしたオブジェクトの復元リクエストを送信 |
| バッチオペレーションからの Lambda 関数の呼び出し | 指定したオブジェクトに対し Lambda 関数によるカスタムアクションを実施 |
| PUT Object ACL | オブジェクトの ACL を更新 |
| PUT Object tagging | オブジェクトのタグを更新 |
S3セキュリティ
バケットは初期状態では限定的なアクセスで作成されますが、権限を誤って公開してしまうとセキュリティ事故に発展します。意識してセキュアなバケットにしていきます。
パブリックアクセスブロック
ユーザーや開発者が誤ってパブリックアクセスを許可しないように、パブリックアクセスを一元管理します。
特殊な要件がない限りは AWS アカウント全体でブロックすることが安全です。
パブリックアクセスブロック設定
パブリックアクセスブロックは4つの設定を組み合わせて設定します。
| 設定項目 | 説明 |
|---|---|
| BlockPublicAcls | パブリックなACL 設定、パブリックなオブジェクトのアップロードをさせない |
| IgnorePublicAcls | パブリックなACL の設定をしていても、それを無力化する |
| BlockPublicPolicy | パブリックなバケットポリシーの設定をさせない |
| RestrictPublicBuckets | パブリックなバケットポリシー設定を持つバケットに対して、パブリックなアクセス、クロスアカウントでのアクセスを無力化する |
パブリックアクセスブロック適用箇所
パブリックアクセスブロックの適用箇所は以下の通りです。
これらのブロック設定が異なる場合は、最も制限の厳しい設定が適用されます。
- アクセスポイント
- バケット
- AWS アカウント全体
アクセス管理
バケットまたはオブジェクトへのアクセスは、アクセスするユーザーとアクセス対象のリソース、それらに対する許可/拒否を設定するアクセスポリシーを作成して管理します。
アクセスポリシーは以下の3つを組み合わせます。
ACL
バケット ACL とオブジェクト ACL が存在します。
ACL を適切に設定することで別アカウントへのアクセス許可や公開バケットを作成することが可能です。
ACL より先にバケットポリシーやユーザーポリシーが評価されるため、現在では ACL を使用することはほぼありません。
バケットポリシーを使いましょう。
バケットポリシー
バケットに設定するポリシーです。このバケットのアクセス権を持つのは誰か という内容を記述します。
バケットポリシーには以下を含めます。
| 要素 | 説明 |
|---|---|
| リソース | 対象のバケット、オブジェクト、アクセスポイント、ジョブを示す |
| アクション | リソースに対するオペレーション。GET、PUT、DELETE など |
| エフェクト | 許可 または 拒否の何れか |
| プリンシパル | アクセス元の IAM リソース、AWS アカウント、AWS サービスなど |
| 条件 | IP アドレスや MFA 制限など特定の条件を指定 |
ユーザーポリシー
バケットやオブジェクトにアクセスする元の IAM ポリシーです。
アクセスする IAM ユーザーやロールに関連付けた IAM ポリシーで対象バケットやオブジェクトのへアクセス許可を明示します。
まずはこれを許可しないことには S3 へアクセスできないので忘れずに許可設定を行います。
逆説的に言うと、IAM ポリシーでバケットをオブジェクトを特定しない「* (アスタリスク)」でリソース許可をしてしまうと、広すぎる権限を与えてしまう可能性があるので注意してポリシーを設定します。
ユーザーポリシーとバケットポリシーの関係を以下に示します。
| ユーザーポリシーを IAM に | バケットポリシーを S3 に | 結果 |
|---|---|---|
| 許可 | 許可 | 許可 |
| 許可 | (設定なし) | 許可 |
| 許可 | 拒否 | 拒否 |
| 拒否 | 許可 | 拒否 |
| 拒否 | (設定なし) | 拒否 |
| 拒否 | 拒否 | 拒否 |
| (設定なし) | 許可 | 拒否 |
| (設定なし) | (設定なし) | 拒否 |
| (設定なし) | 拒否 | 拒否 |
MFA Delete
誤った削除を防止することを目的とした方式です。
バケットを削除する際にポリシーのよる認証に加え、デバイス(ハードウェア または ソフトウェア) で生成されたコードを使います。
保管時の暗号化
保管されるデータの暗号化には、サーバー暗号化とクライアント暗号化に2種類があります。
サーバー側の暗号化
サーバー側、つまり AWS 内にデータが保存される際に暗号化され保存されます。
認証されたユーザーがオブジェクトにアクセスすると復号化されます。
サーバー暗号化には3つのオプションがあります。併用することはできません。
Amazon S3 が管理するキーによるサーバー側の暗号化 (SSE-S3)
S3 が管理するキーによって暗号化を行います。
キー管理の手間が軽減されます。
よりセキュアにするためにはキーの定期ローテーションを行います。
AWS Key Management Service に保存されているカスタマーマスターキー (CMK) によるサーバー側の暗号化 (SSE-KMS)
Key Management Service にユーザーが作成したキーをアップロードし、そのキーで暗号化します。
追加料金がかかりますが、セキュリティ要件にユーザーが作成した暗号化キーを使うと指定されている場合に有用です。
ユーザーが指定したキーによるサーバー側の暗号化 (SSE-C)
ユーザーが管理しているキーを使用してオブジェクトをサーバー側で暗号化します。
AWS に暗号化キーは保管されません。
クライアント側の暗号化
データを S3 へ送信する前にクライアントで暗号化する方式です。
AWS KMS に保存されているマスターキー、または、アプリケーションに保管されているマスターキーを使ってデータ暗号化し、S3 へ送信します。
S3 からのダウンロー時の復号化もアプリケーションで実装します。
転送中の暗号化
S3 は HTTPS で通信します。
公開設定をした場合、HTTP でアクセス可能になってしまいます。バケットポリシーで aws:SecureTransport 条件を使用して、HTTPS (TLS) を介した暗号化接続のみを許可します。
オブジェクトロック (WORM)
Write Once Read Many (WORM) モデルを使用してオブジェクトを保護します。
オブジェクトロックをすることで、一定期間乃至無期限にオブジェクトの削除や上書きを防止します。
オブジェクトロックでは2つのリテンションモードが提供されます。
ユーザーが定義した保持期間中は、リテンションモードの動作によったオブジェクト保護が提供されます。
ガバナンスモード
特別な権限を持ったユーザーのみがオブジェクトバージョンの削除や上書きが可能です。
コンプライアンスモード
AWS アカウントの root ユーザーを含めた全ユーザーが、保持期間中のオブジェクトバージョンの削除や上書きが不可能になります。
リーガルホールド
保持期間とは関係なく任意のオブジェクトバージョンを保護することが可能です。
リーガルホールドを提供すると明示的に解除するまでデータを保護します。
リーガルホールドは特定のアクセス許可を持ったユーザーのみが適用/解除が可能です。
S3 サーバーアクセスログ
バケットに対するリクエストの詳細を記録します。
アクセス監査やアクセス分析に活用します。
アクセスログはアクセスログ用のバケットを作成し保管します。
アクションの記録
IAM ユーザー/ロール、AWS サービスのよって行われた S3 に対するアクションを記録するために CloudTrail を有効にします。
フォレンジック調査に活用します。
Macie
S3 に保管された個人情報や知的財産などの機密データを自動的に検出、分類、保護するサービスです。
例えば、クレジットカード番号が保管されたファイルが誤ってアップロードされた際には検出をすることが可能です。
S3パフォーマンス
S3 はリクエストに応じて自動的にスケールします。
バケット内のプレフィックスごとに 1 秒あたり 3,500 回以上の PUT/COPY/POST/DELETE リクエストまたは 5,500 回以上の GET/HEAD リクエストを達成する可能性があります。
同一のリクエストが大量に発生する場合にはプレフィックスを適切に分割します。
プレフィックスは論理グループです。ディレクトリのようなものです。
以下の例では日付をプレフィックスにしています。
awsexamplebucket/2018-01-28/photo1.jpg awsexamplebucket/2018-01-28/photo2.jpg awsexamplebucket/2018-01-30/photo1.jpg awsexamplebucket/2018-01-31/photo1.jpg awsexamplebucket/2018-01-31/photo2.jpg awsexamplebucket/2018-01-31/photo3.jpg
S3 のパフォーマンスガイドライン
パフォーマンスメトリクスの測定
どこにボトルネックがあるかを明確にするためにパフォーマンスメトリクスを測定します。
S3 のメトリクスは CloudWatch で取得されています。
送受信側でもリソース使用率(CPU、メモリ、ネットワーク、DiskIO)や DNS ルックアップ などのメトリクスを取得しておきます。
水平スケール
S3 への GET/PUT などは直列処理にせず並列に実行したほうがパフォーマンスが優れるように設計されています。
大きなサイズのファイルを PUT する場合はマルチパートアップロードを使用します。
例えば、1GB のファイルを1回で送るより 100MB に分割して10並列で送ったほうが高速になります。
マルチパートアップロードは SDK や CLI により実装可能です。
GET する場合は Range HTTP ヘッダーを使い分割してダウンロードします。
マルチパートアップロードの逆版です。
タイムアウトと再試行の実装
S3 へリクエストを発行するアプリケーションではタイムアウトと再試行を実装します。
AWS SDK を使用すると自動再試行ロジックを実装可能です。
AWS でのエラー再試行とエクスポネンシャルバックオフ
S3 は持続された新しいリクエスト率に応じて自動的にスケールします。
レスポンスが遅いリクエストの再試行をしていくとパフォーマンスが向上することがあります。
Amazon S3 Transfer Acceleration を使用
AWS リソースは必要とするバケットと同一リージョンに作成します。
オンプレミスの場合は最寄りのリージョンを使用します。
また、S3 Transfer Acceleration を使用することで離れたリージョンへのリクエストを高速化することが可能です。
Amazon S3 Transfer Acceleration 速度比較ツール
S3ユースケース
ウェブサイトホスティング
S3 をウェブサイトの静的コンテンツ置き場として利用します。
動的コンテンツや背後に DB が必要なコンテンツは Web サーバーに配置します。
前段には CloudFront を設置し、キャッシュによるパフォーマンス向上や DDoS 対策、WAF を活用したサイトの防御を行います。
データレイク
データレイクの基盤として S3 を利用します。
ローコスト、スケーラビリティ、高耐久性、セキュリティなど S3 のメリットを充分に活かすことが可能です。
S3 を基盤としてデータレイクは以下のようなケースで活用します。
- データアナリティクス
- ML
- AI
- データインテグレーション
- ログ収集と分析
参考
AWS でのデータレイクと分析
AWS で構築するデータレイク基盤と amazon.com での導入事例
バックアップやデータ退避先
大量のデータを保管しておく場所として S3 は最適です。
以下のようなデータを S3 へ保管すると比較的安価で耐久性が高いソリューションを実現します。
- データベースダンプファイルの世代保管
- DR を目的でのデータ疎開
- コンプライアンス要件によるファイルの長期保管
- アプリケーションのファイルスペース
サーバーから S3 へファイルを転送する方法
サーバー上のファイルを S3 へ転送する方法はいくつか存在します。
目的に合わせて最適な方法を選択することが可能です。
NFS/SMB を用いてファイル転送
サーバーから NFS または SMB を用いてファイルを S3 へ転送するには AWS Storage Gateway を使用します。
オンプレミス または EC2 にアプライアンスをデプロイすると NFS/SMB のマウントポイントが作成可能になります。
そこをサーバーからマウントする形になります。
キャッシュサイズを適切に設定すれば一定のパフォーマンスは実現できます。
非同期で定期的にファイル転送
サーバー上のファイルを定期的に S3 へ転送したい場合は AWS DataSync を使用します。
オンプレミス または EC2 に DataSync エージェントをデプロイします。
DataSync エージェントは NFS/SMB マウントポイントをマウントして、そこにあるデータを S3 へ転送します。
DataSync はデータ転送に専用プロトコルを採用しているとされ、通常より転送速度が高速なので大量のデータを送信するケースに向いています。
例えば、バックアップサーバーのデータを D2D2S3 (Disk-to-Disk-to-S3) で統合するなどです。
一般的なコマンドを用いてインターネット経由でファイル転送
SFTP、FTPS、FTP といった一般的なコマンドを用いてファイルを S3 へ転送するには AWS Transfer Family を使用します。
外部組織からのファイル転送はこの方式が向いています。
おまけ
同じものを GitHub にあげてますのでそちらも参照ください。
参考
Amazon Simple Storage Service ドキュメント
Black Belt
S3 特集カテゴリー
以上、吉井 亮 がお届けしました。









